[AINews] Perplexity, the newest AI unicorn • ButtondownTwitterTwitter
Chapters
AI Discord Recap
Fine-tuning and Optimizing Large Language Models
Eleuther Discord
Discord Channel Discussions
Unsloth AI Discussions
Sharing Perplexity AI Updates
Interesting Links Discussion
LM Studio and Models Discussion Chat
Troubleshooting and Queries on LM Studio
CUDA Mode Intermediate Results
Evaluation and Integration of New Models and Technologies
HuggingFace Discord Highlights
Performance and Benchmarks
OpenAccess AI Collective (axolotl)
Anticipating Model Updates and Additions
Discussion on AI Models, OpenAI Dependencies, and Document Summarization
Evaluation and Benchmarking Discussions
DiscoResearch Discussions
Improving Medical Information Accessibility
AI Discord Recap
AI Discord Recap
A summary of Summaries of Summaries
1. Evaluating and Comparing Large Language Models
- Discussions around the performance and benchmarking of the newly released Phi-3 and LLaMA 3 models, with skepticism expressed about Phi-3's evaluation methodology and potential overfitting on benchmarks like MMLU.
- Comparisons between Phi-3, LLaMA 3, GPT-3.5, and models like Mixtral across various tasks, with Phi-3-mini (3.8B) showing impressive performance relative to its size.
- Debates around the validity and usefulness of benchmarks like MMLU, BIGBench, and LMSYS for evaluating true model capabilities.
- Anticipation for the open-source release of Phi-3 under an MIT license and its promised multilingual capabilities.
2. Advancements in Retrieval-Augmented Generation (RAG)
- LlamaIndex introduced DREAM, a framework for experimenting with Distributed RAG.
- Discussions on innovative RAG techniques like Superposition Prompting for efficient long context processing and CRAG for improving retrieval quality.
Fine-tuning and Optimizing Large Language Models
Fine-tuning and Optimizing Large Language Models
-
Extensive discussions on fine-tuning strategies for LLaMA 3 using tools like Unsloth, addressing issues like tokenizer configurations, efficient merging of LoRA adapters, and embedding knowledge.
-
Comparisons between full fine-tuning, QLoRA, and LoRA approaches, with QLoRA research suggesting potential efficiency gains over LoRA.
-
Implementing mixed-precision training (BF16/FP16) for llm.c showing ~1.86x performance improvement over FP32, as detailed in PR #218.
-
Optimizations in llm.c like CUDA kernel improvements (GELU, AdamW) using techniques like thread coarsening to enhance memory-bound kernel performance.
Eleuther Discord
Discussions in the Eleuther Discord community explored various topics related to the feasibility of running large language models on smartphones, the introduction of new byte-level LLM architecture with SpaceByte, and the integration of RWKV in GPT-NeoX development. Furthermore, AI's role in designing high-performance proteins was showcased, emphasizing the expanding utility of LLMs in biotechnology sectors.
Discord Channel Discussions
Skunkworks AI Discord
-
Surprise in Context Size: Members learned about a certain AI operating with a 32k context size, challenging previous assumptions.
-
Alternate Methods to Model Scaling: Alpin's innovative approach to scaling AI models without 'rope'.
-
Matt Rolls Out 16k Config for Llama: Matt shared a configuration for the Llama model with max_position_embeddings at 16000.
-
Medical Knowledge Simplification: Discussions focus on making medical knowledge accessible by fine-tuning LLMs and developing agentic systems.
-
OCR Data Hunt for Lesser-Known Languages: Efforts to find OCR datasets for less-popular languages to expand AI's linguistic reach.
LLM Perf Enthusiasts AI Discord
-
Meta AI's 'Imagine' Intrigues Engineers: Meta AI's 'Imagine' captivated users, prompting requests for examples.
-
Focus on Development Tools for LLMs: Members seek optimal dev tools for Large Language Models work.
-
Azure OpenAI Service Challenges: Users express frustrations with Azure OpenAI, facing significant latency and rate-limiting issues.
-
Tracking API Responses with GPT for Work: A real-time API response tracker shared to monitor LLMs' API performance.
Unsloth AI Discussions
Members of the Unsloth AI community engaged in various discussions related to model training, quantization, model showcasing, technical issues, and future directions. Some of the key topics included fine-tuning LLaMA models, exploring quantization effects, setting up Unsloth environments, challenges with inference using finetuned models, exporting models, and fine-tuning strategies. Additionally, new models like Ghost 7B Alpha and solobsd-llama3 were introduced, and technical exchanges on model generation and working with datasets were shared among community members. The discussions also touched on workflow challenges in Google Colab, SSH access issues, and potential directions for Unsloth Pro, including suggestions for philanthropic pursuits and model compatibility.
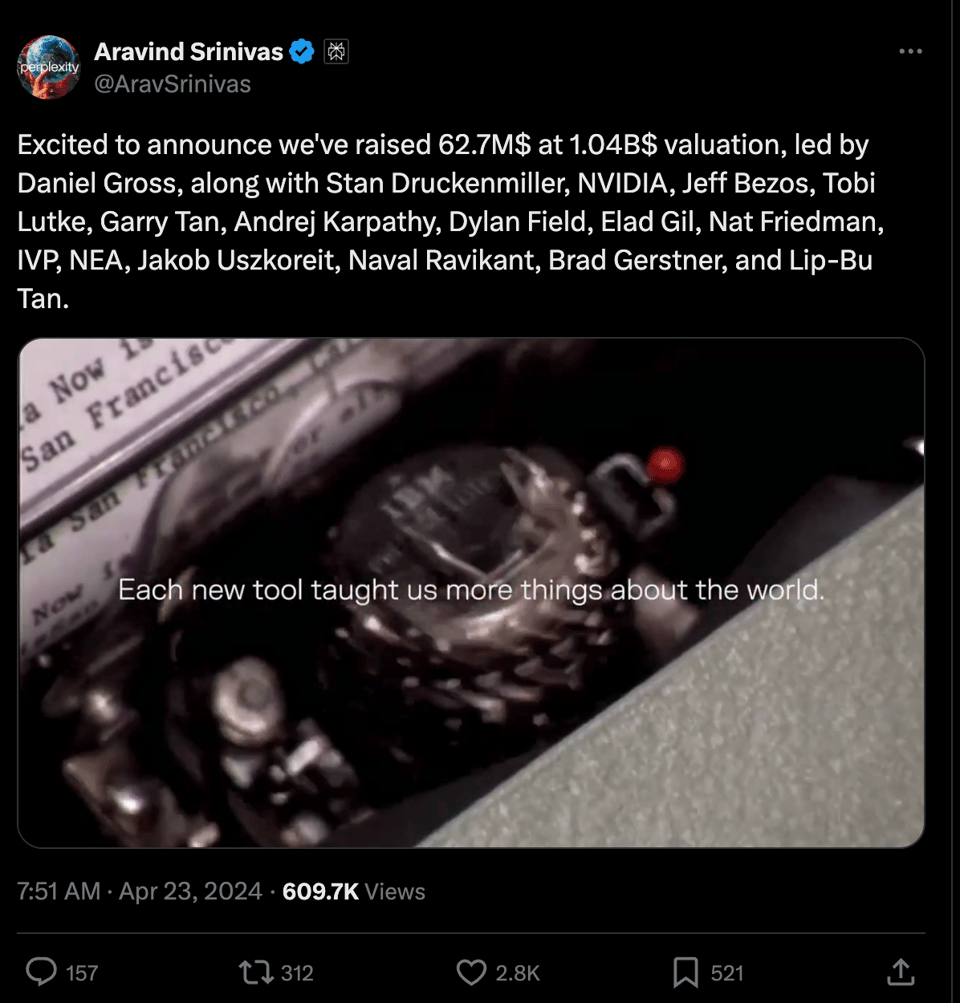
Sharing Perplexity AI Updates
The Perplexity AI channel showcases the latest updates on the Perplexity Enterprise Pro launch, pricing, and impacts on businesses. The channel also discusses the general happenings at Perplexity AI, including discussions on its valuation, growth, potential features, and upcoming releases. Moreover, there are shared links to various news articles and interviews related to the company's developments and achievements.
Interesting Links Discussion
The discussion in this section covers various interesting links and topics related to AI research and advancements in the field. It includes discussions on new tools like Google DeepMind's Penzai for neural networks, calls for beta testers for advanced research assistants, exploration of loss curves in training large language models, the release of a new toolkit for AI vision models, confusion over dataset purposes, and interest in additional benchmark datasets for testing AI models. Topics also range from fine-tuning guidelines for LLMs to practical applications of RAG prompting methods. Overall, the section highlights diverse conversations on AI technologies and methodologies.
LM Studio and Models Discussion Chat
Users in the LM Studio and Models Discussion Chat are engaging in various discussions related to LM Studio's performance, issues with Hugging Face downtime, creating system prompts for specific scenarios, troubleshooting technical issues, exploring different AI model quantizations, and sharing feedback and feature requests. Topics include concerns about running LM Studio on different GPUs, performance comparisons between Llama 3 and alternative models, evaluating Phi-3, and seeking assistance on LM Studio's capabilities and model handling. There are also discussions on content creation restrictions, implementing fixes for model generation issues, and considerations for future AI simulations.
Troubleshooting and Queries on LM Studio
This section delves into various troubleshooting issues and user queries related to LM Studio. Users reported encountering issues like model loading errors, unexpected model behavior, VPN certificate problems, and errors related to Hugging Face models in LM Studio. Additionally, there are discussions on configuring prompts, seeking assistance for directory structures in LMStudio, understanding tokenizations, and optimizing hardware for using LLMs. The section also covers inquiries about projects integration, models for research papers, and GPU utilization on AMD hardware.
CUDA Mode Intermediate Results
In this section, it was explained how operations on the GPU are scheduled asynchronously, meaning Python instructions return before the computation is complete. Blocking or synchronizing operations that require reading the value will cause synchronization with the CPU. Additionally, there is an announcement about a lecture on Cutlass starting in CUDA MODE, discussions on ongoing CUDA lectures and upcoming schedules, matrix multiplication explorations in CUDA, image and video processing projects using CUDA, and hardware selection for machine learning systems. There are also discussions on challenges faced with DenseFormer in JAX due to high memory usage, exploration of write-once buffers, and considerations for custom gradients for lean memory footprint. Lastly, there are discussions on implementing training with Ring Attention and topics ranging from regional meetups in Münster to technical discussions on Triton Kernel benchmarks, transposing for better backward pass efficiency, quantization considerations, and kernel optimization and profiling.
Evaluation and Integration of New Models and Technologies
In this section, various discussions took place around evaluating technological capabilities of smartphones for local LLM use, examining existing apps like MLC-LLM, debating business models like Hugging Face, exploring reasoning methods beyond CoT, and analyzing the cost implications of training large models. Additionally, conversations in Eleuther channels involved topics such as diffusion model inference steps, token-free language models, concerns about datasets, AI-designed CRISPR-Cas proteins, and prioritizing prompts for safe LLMs. These discussions demonstrate a wide array of research and development activities in the field of large language models and AI technologies.
HuggingFace Discord Highlights
This section highlights various discussions and updates from different channels on HuggingFace Discord:
- Downtime concerns and integration questions were discussed in the 'general' channel.
- Members in the 'today-im-learning' channel shared insights on studying AI speed, reinforcement learning, tokenization, and RAG systems.
- The 'cool-finds' channel featured discussions on quantum computing, neural networks, voice-prompted AI image generation, offline RL frameworks, and interactive JavaScript for Transformers.
- The 'i-made-this' channel showcased projects related to math PDFs, real-time video generation, Infini Attention, innovative bot programming, and the 3LC platform.
- The 'computer-vision' channel discussed invoice data extraction, TrackNetV3 processing, and personal knowledge base construction.
Performance and Benchmarks
In this section, various discussions related to performance and benchmarks in Mojo are highlighted. The topics range from exploring performance with CPU limits to seeking the optimal parallelize strategy. Members discuss multithreading complexities and best practices, including setting the number of workers. Additionally, performance puzzles in random number generation are explored, with a member sharing a slower Mojo script for calculating pi and opening an issue on GitHub to address random number generation performance.
OpenAccess AI Collective (axolotl)
The Axolotl channel on Discord witnessed discussions regarding various AI-related topics. Members talked about troubleshooting issues with updates, handling GPUs and training times, the efficiency of Phi-3 models, OpenAI's strategies, licensing of Phi series models, and more. Discussions included fine-tuning LLaMa 3 models, the performance of GPUs, and the exploration of 8-bit optimizers. Members also addressed string comparisons, pointer semantics, and string representations, delving into technical details and solving dilemmas. Throughout, the community shared insights, helpful links, and encouraged contributions to the ongoing conversations.
Anticipating Model Updates and Additions
Enthusiasts are eagerly anticipating the release of new models such as LLaMA 3 70b and WizardLM-2, speculating on their possible connections with Microsoft. Users on OpenRouter await uncensored versions of LLaMA 3 70b, discuss the significance of jailbreakable models, and ponder the potential arrival of Phi-3 on the platform. Preferences for the 8x22 models are noted, emphasizing the balance between cost and functionality. Meanwhile, the community compares AI writing styles, speculates on RWKV's future, and discusses the performance of various AI models like GPT-5.
Discussion on AI Models, OpenAI Dependencies, and Document Summarization
In this section, various discussions were held on topics related to AI models, open-source dependencies, and challenges in document summarization. Members debated on the choice of retrieval methods like RAG, CRAG, and retanking, emphasizing the importance of use-case specificity. Integration challenges were shared, including frustration over context management issues within a Retriever-Answer Generator (RAG) system. Questions were raised about alternative AI models like Groq, Bedrock, and Ollama, with clarifications provided on API key errors and correct embedding model usage. Additionally, issues regarding indexing and storage using Vector Stores such as Supabase, Chromadb, and Qdrant were discussed, highlighting warnings and errors related to OpenAI's API key. Moreover, a member sought advice on enhancing summarization using DocumentSummaryIndex to consider all nodes for summarization rather than selecting just one node. Links to relevant documentation and resources were also provided for further exploration.
Evaluation and Benchmarking Discussions
Evaluations Categorization in the Spotlight
A member discusses the Evals section of their research and touches on the immediate utility of automated evaluations like MMLU and BIGBench versus time-costly human evaluations like ChatBotArena.
The Role of Perplexity-Based Evals
The same member questions the role of perplexity-based evaluations like AI2's Paloma and how they compare to task-based evaluations such as MMLU. There's uncertainty about whether Paloma was intended just for internal checks during training or as a broader public benchmark.
Benchmark Categorization Approval
Both members express appreciation for a categorization of benchmarks from the MT Bench paper, indicating that it provides a helpful framework, even though the categorization of tools like Paloma isn't clear-cut.
Utility of Multi-Dataset Perplexity-Based Metrics in Training
A member ponders if multi-dataset perplexity-based evaluations are more about monitoring model performance at training checkpoints rather than for post-completion model competitions. They seek confirmation on this understanding.
Confirming Perplexity's Role
Another member confirms that perplexity-based evaluations are indeed used as checkpoints during training, rather than as competitions for completed models, though it is a relatively new concept for them as well.
DiscoResearch Discussions
tinygrad
- tinygrad with ROCm Hurdles: Setting up tinygrad with ROCm encounters issues post the ROCm 6.1 release.
- Stacking Tensors in tinygrad: Explanation on tensor stacking and materializing computations in tinygrad.
- Master Branch Stability for tinygrad: Assurance of stability in the master branch of tinygrad due to CI processes.
- CUDA Compatibility and Windows Limitation: Challenges using tinygrad with CUDA on Windows discussed.
- In-Depth Guidance on tinygrad Mechanics: Resources shared for understanding deep aspects of tinygrad.
DiscoResearch
- Llama3 vs. Mixtral Face-Off: Evaluation results comparing Llama3 and Mixtral models discussed.
- Metric Discrepancies Questioned: Concerns raised about evaluation metric discrepancies.
- Potential Formatting Bug Spotted: Highlight of a formatting bug in the query template.
- Request for Command-R-Plus Comparison: Comparison requested between Llama3 and command-r-plus models.
- DiscoLM German 7b Evaluation Details Shared: Detailed evaluation results shared for DiscoLM German 7b.
Latent Space
- Stretching the Context Window with Rope: Discussion on extending context window using rope.
- High Quality Web Data Release, FineWeb: Release of FineWeb with 15 trillion web data tokens discussed.
- Hydra Framework Spurs Varied Reactions: Experiences shared on the Hydra framework.
- Phi-3 Gains Weight: Release of Microsoft's Phi-3 model detailed.
- Perplexity.ai Fundraising Success: Mention of Perplexity.ai's recent fundraising success.
Improving Medical Information Accessibility
The section discusses various strategies to improve the accessibility of medical information to patients with lower educational backgrounds. It includes suggestions such as developing an agentic system for managing tasks, transitioning medical jargon to simpler terms, utilizing data-driven fine-tuning, and highlighting the efficiency of using an agent for simplification tasks. The content also briefly touches on discussions related to AI tools and challenges faced with AI models such as Azure OpenAI and Llama 3.
FAQ
Q: What are some key discussions around evaluating and comparing large language models like Phi-3 and LLaMA 3?
A: Discussions include skepticism about Phi-3's evaluation methodology, comparisons with models like GPT-3.5 and Mixtral, debates on benchmark validity (MMLU, BIGBench), and anticipation for Phi-3's open-source release.
Q: What advancements have been made in Retrieval-Augmented Generation (RAG) techniques?
A: Advancements include the introduction of DREAM framework, innovative techniques like Superposition Prompting and CRAG, and discussions on improving retrieval quality.
Q: What are some of the fine-tuning strategies discussed for LLaMA 3 models?
A: Discussions focus on fine-tuning strategies using tools like Unsloth, addressing issues with tokenizer configurations, merging LoRA adapters efficiently, and exploring mixed-precision training for performance improvements.
Q: What are some topics discussed within the Eleuther Discord community regarding large language models?
A: Discussions include the feasibility of running large models on smartphones, new byte-level LLM architecture like SpaceByte, and AI's role in designing high-performance proteins for biotechnology sectors.
Q: What are some challenges and discussions surrounding LM Studio and its usage?
A: Challenges include troubleshooting issues like model loading errors, unexpected model behavior, and VPN certificate problems. Discussions also cover prompts configuration, directory structures, and GPU optimizations for using LLMs.
Q: What were some notable discussions in the AI-related channels on HuggingFace Discord?
A: Discussions range from downtime concerns to exploring different AI models like Penzai, beta testing requests for research assistants, and practical applications of RAG prompting methods.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!