[AINews] Contextual Position Encoding (CoPE) • ButtondownTwitterTwitter
Chapters
Contextual Position Encoding (CoPE)
AI Discord Recap
Discord Community Highlights
Discord Community Highlights
LLM Finetuning (Hamel + Dan) Learning Resources
Fine-Tuning and Troubleshooting Discussions
LangChain and LangSmith Discussion
HuggingFace - Reading Group
HuggingFace - LM Studio Discussions
Eleuther Research
Eleuther Discussion on MLP-Mixers and Transformers
CUDA, Storage Optimization, and Kernel Recomputations
Nous Research AI - Shared Techniques and Concerns
Mojo Nightly, Modular (Mojo), OpenRouter, OpenRouter (Alex Atallah), OpenRouter (Alex Atallah), and OpenRouter (Alex Atallah)
Latent Space AI General Chat
Email Subscription Form and Social Media Links
Contextual Position Encoding (CoPE)
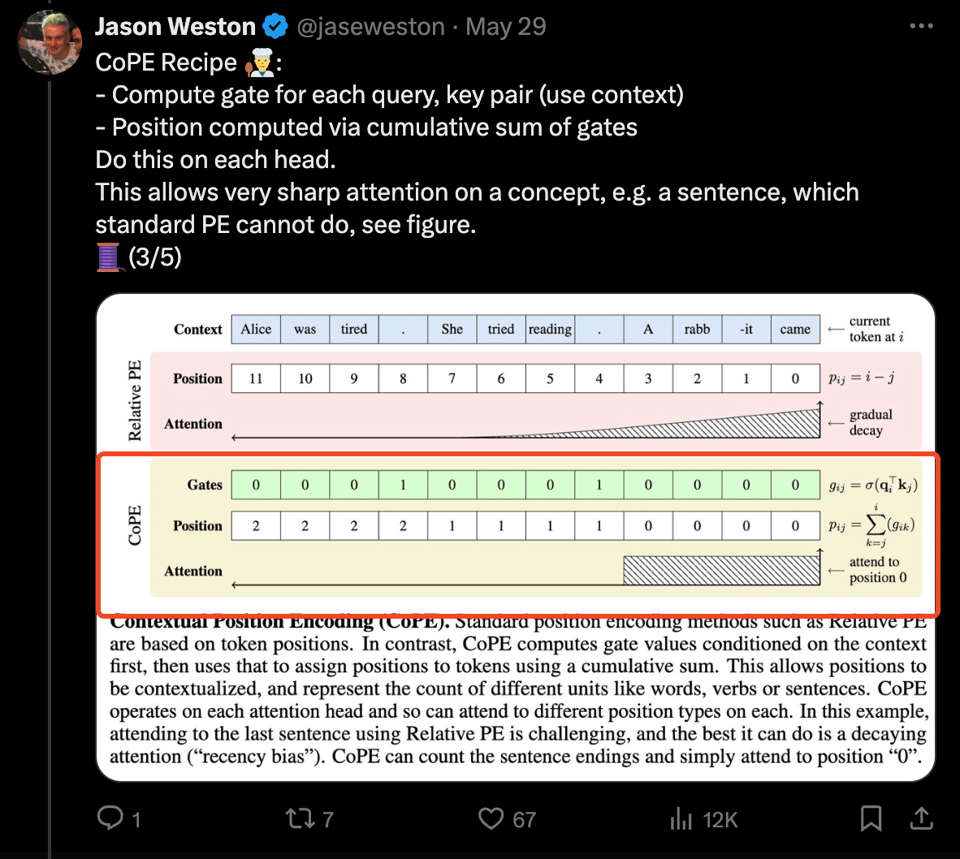
AI News for 5/29/2024-5/30/2024. We checked 7 subreddits, 384 Twitters and 29 Discords for you. Estimated reading time saved: 478 minutes. A quiet day, but the CoPE paper got some buzz. Traditional LLMs have known issues with simple algorithmic tasks like counting and copying, likely due to their positional encoding strategy. Jason Weston of Meta AI released his paper on CoPE, a new positional encoding method for transformers that takes into account context, creating 'gates' with learnable indices. CoPE LLM can count distances per head dependent on need, solve tasks that standard transformers cannot, and achieve better PPL on language modeling + coding tasks. The concept can even be modified to use external memory for calculating the gates. The position encoding variants this year add missing capabilities to models, making linear attention about removing model capacity and position embedding about adding capabilities.
AI Discord Recap
The AI Discord recap section highlights various discussions and developments in the AI community. It covers topics such as new AI model releases, fine-tuning techniques, optimizations in AI systems, competitions, and open initiatives. The section also includes updates on partnerships, advancements in AI systems, and advancements in AI hardware and performance. The community engages in vibrant discussions around AI ethics, physics, model performance, and more, reflecting a diverse and active AI community.
Discord Community Highlights
The Discord communities continue to be active with various discussions and updates. In the Nous Research AI Discord, topics included enhancing model performance through context-specific prompts, exploring novel training approaches, and the emergence of the Yuan2-M32 model. Over in the Modular (Mojo 🔥) Discord, conversations revolved around ABI stability in Swift and Rust, skepticism over Mojo's potential, and discussions on C++ interoperability. On the OpenRouter (Alex Atallah) Discord, the launch of MixMyAI garnered attention, discussions around accessing free tiers, and announcements about talent availability for new collaborations.
Discord Community Highlights
This section highlights key discussions and developments from various Discord communities related to AI, including Cohere, LangChain AI, Interconnects, OpenInterpreter, and more. The discussions range from community contributions to new AI models, technical challenges, market strategies, and potential collaborations in the AI field.
LLM Finetuning (Hamel + Dan) Learning Resources
A member shared a meta paper released by AI at Meta relevant for vLLM. Find the paper here. Another member initiated a GitHub repository collecting resources on LLMs, beneficial for participants in the 'Mastering LLMs' workshop. You can access and contribute to the repo here. Additionally, a paper discussing the extension of LLama3's context window from 8K to 80K was shared. The resource set including data, model, data generation pipeline, and training code will be publicly released here. Lastly, there is a Humble Bundle available for AI-coding and prompt engineering, which might interest the community. More details and purchase options are available here.
Fine-Tuning and Troubleshooting Discussions
The section covers various discussions related to fine-tuning large language models (LLMs) and troubleshooting issues encountered during the process. Users discuss running LLMs on different platforms, debugging tokenizer issues, setting up billing prerequisites for certain tasks, and exploring compliance options for specific frameworks like HIPAA. The section also includes insights on the effectiveness of different Text2SQL methods, the debate between Copilot and Cursor functionalities, and the utilization of JSON Schema and Zod for function calling. Additionally, evaluation processes for LLMs, scoring tools, and best practices for model evaluation, integration, and deployment are highlighted in this section.
LangChain and LangSmith Discussion
The LangChain and LangSmith tools were discussed in this section. LangChain provides development and deployment tools, while LangSmith offers inspection and optimization capabilities. Users shared clarification on the distinctions, tools usage, and best practices. Links to resources for deeper understanding were exchanged, including an O'Reilly post, a GitHub repository, and a YouTube series on LangChain LangGraph. Community members praised the tools' flexibility, project experiences, and potential integrations for compliance.
HuggingFace - Reading Group
- PPO without a reference model query sparks interest: A user inquired about using PPO without a reference model, seeking assistance for an internship project deadline. Another member suggested looking into SimPO as an alternative that eliminates the need for a reference model, offering an arXiv link for further reading.
- New mathematical improvements in AI models excite members: A paper shared on Hugging Face detailing math advancements in AI models, particularly in reinforcement learning, generated excitement among members. Another paper on 'Direct Preference Optimization' was mentioned, highlighting SimPO as a more efficient alternative to traditional reference-model-based approaches.
HuggingFace - LM Studio Discussions
This section includes various discussions from HuggingFace's LM Studio channels. Users share information on model releases, fine-tuning tasks, monocular depth estimation, and best practices for fine-tuning transformers. There are also discussions on model context lengths, challenges with model compatibility, and recommendations for specific programming languages. Additionally, conversations cover hardware discussions such as crypto mining for burn-in tests, NVIDIA's new GPU rumors, and the cost-effectiveness of high-end hardware for inference. Lastly, users discuss concerns about AI-generated information quality and techniques to mitigate hallucinations.
Eleuther Research
Constant learning rate vs. Cosine schedule:
An arXiv paper argues that constant learning rates with cooldowns scale predictably and reliably, similar to cosine schedules. Stochastic weight averaging is shown to improve performance without extra training costs.
Contextual Position Encoding (CoPE) introduced:
A tweet by @jaseweston discusses CoPE, a new positional encoding method for transformers that accounts for context. It can handle counting and copy tasks and shows better performance on language modeling and coding tasks.
Sonic: fast generative voice model released:
Cartesia AI announced the release of Sonic, a generative voice model with 135ms model latency, part of their mission to build real-time multimodal intelligence.
Gradient diversity affects mini-batch SGD performance:
An arXiv paper suggests that high similarity between gradients degrades mini-batch SGD performance. Gradient diversity is crucial for speedups while maintaining performance.
Model Merging competition at NeurIPS:
NeurIPS 2023 will feature a model merging competition with up to $8,000 in prizes. The competition is sponsored by organizations including Hugging Face and Sakana AI Labs.
Eleuther Discussion on MLP-Mixers and Transformers
MLP-Mixer Struggles for Causality and Sequence Length: Members discussed challenges in making MLP-mixers causal and effective across various sequence lengths, noting the need for 'weird tricks' for universal applicability.
Transformers as Dynamic MLP-Mixers: The discussion highlighted transformers as context-dependent MLP-mixers, with attention viewed as dynamically generated weights over time.
Criticism and Alternatives to MLPs vs Transformers: Criticism was laid on the practicality and superiority of MLPs over transformers, emphasizing the need for context-dependent operations.
Industry Preference for Transformers: The dominance of transformers in industry over MLPs was reiterated, with past technology preference trends cited.
Exploring Alternatives and Integration in Diffusion Models: Members discussed diffusion models in robotics and the interest in hybrid models for versatile integration.
CUDA, Storage Optimization, and Kernel Recomputations
In this portion, discussions were held regarding various optimizations and strategies related to CUDA performance, storage cost reduction, and kernel recomputations. A focus was placed on utilizing templated block sizes for improved CUDA kernel performance. Additionally, suggestions were made concerning the use of internal S3 storage to avoid additional fees by pre-uploading resources. Another proposal involved merging and optimizing kernel recomputations to enhance code integration and functionality. Further improvements were discussed for this approach to reduce redundant computations and enhance performance. Links to key discussions and references were also provided for more in-depth exploration.
Nous Research AI - Shared Techniques and Concerns
Members of the Nous Research AI group shared various in-context learning techniques, including the use of prompts to enhance model performance. Efficient data processing concerns were raised, with a focus on feeding extensive data to models efficiently. Additionally, the idea of training models without backpropagation was proposed, and an example of successful in-context learning was highlighted. The group also discussed the importance of hybrid search, relevance metrics, and shared a new RAG dataset. Overall, the discussions focused on improving AI models through innovative techniques and addressing challenges in data processing and training.
Mojo Nightly, Modular (Mojo), OpenRouter, OpenRouter (Alex Atallah), OpenRouter (Alex Atallah), and OpenRouter (Alex Atallah)
The update for Mojo Nightly build 2024.5.3005 brings critical changes like the removal of Stringable constructor from String and math functions. Approximately 25% of Mojo installs are from nightly builds for user simplicity. Users report errors from Stringable constructor removal. CI for public Mojo repo fixed issues due to String.strip() changes. Using setitem with list capacity does not update list length; append is recommended. OpenRouter discussions include launch excitations, seeking developers, Gemini Pro Ratelimit, and Laravel/Ruby integration. OpenInterpreter discussions cover the LiteLLM models, mobile client anticipation, heat issues with local LLMs, TTS voice integration, and shipping inquiries. The excitement for M5 cardputer updates in the O1 channel is evident.
Latent Space AI General Chat
Latent Space ▷ #ai-general-chat (17 messages🔥):
-
OpenAI expands ChatGPT Free offerings: Discussion on the addition of new features to the ChatGPT Free tier, including browse, vision, data analysis, and more, with hints at possible rate limits. OpenAI's announcement details these updates.
-
A16Z investment thesis on voice AI: Mention of a new investment thesis by a16z focusing on conversational voice agents and the impact of AI on phone calls, amidst doubts on separating technical progress from investment hype.
-
Cartesia's state space voice model launch: Discussion on the launch of Sonic by Cartesia, a generative voice model with real-time multimodal intelligence for devices. Implications for AI explored with links to their blog post and a demo link.
-
YC clarifies Sam's departure: Paul Graham's tweet clearing misconceptions about Sam's departure from Y Combinator.
-
Embedding Adapters for retrieval: Discussion on TryChroma's technical report highlighting embedding adapters to enhance retrieval performance, with mentions of similarities to Vespa's frozen embeddings approach and a related blog post.
Email Subscription Form and Social Media Links
The section displays an email subscription form for AI News with an input field for the email address and a 'Subscribe' button. Additionally, there are links to the AI News Twitter account and to the newsletter on the latent.space website. The footer also includes social media links and information that the newsletter is brought to you by Buttondown, a platform for newsletters.
FAQ
Q: What is the CoPE positional encoding method for transformers?
A: CoPE is a new positional encoding method for transformers introduced by Jason Weston of Meta AI. It considers context by creating 'gates' with learnable indices, enabling the model to count distances per head as needed and solve tasks standard transformers struggle with. CoPE can even utilize external memory for calculating the gates.
Q: What are some advantages of CoPE over traditional positional encoding strategies in transformers?
A: CoPE offers improved performance on language modeling and coding tasks compared to traditional transformers. It can handle tasks like counting and copying more effectively due to its context-aware 'gates' with learnable indices, which enhance the model's ability to understand positional information.
Q: How do CoPE variants this year enhance transformer models?
A: The position encoding variants introduced this year enhance transformer models by adding missing capabilities. They focus on making linear attention more efficient by removing unnecessary model capacity while improving position embedding to add new capabilities to the models, resulting in overall performance enhancements.
Q: What was the key finding in the arXiv paper about constant learning rates and cosine schedules?
A: The arXiv paper argued that constant learning rates with cooldowns can scale predictably and reliably, similar to cosine schedules. It also highlighted that Stochastic Weight Averaging can improve performance without incurring extra training costs.
Q: What was the focus of discussions around Sonic, the fast generative voice model released by Cartesia AI?
A: Discussions around Sonic, the fast generative voice model, centered on its key feature of having a model latency of 135ms, contributing to real-time multimodal intelligence. The release signifies Cartesia AI's commitment to building efficient and fast voice models for various applications.
Q: How did the paper on 'Direct Preference Optimization' propose a more efficient alternative to traditional reference-model-based approaches?
A: The paper on 'Direct Preference Optimization' highlighted SimPO as a more efficient alternative to traditional approaches that rely on reference models. SimPO eliminates the need for a reference model, streamlining the optimization process for AI models, particularly in the context of reinforcement learning.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!