[AINews] Cohere Command R+, Anthropic Claude Tool Use, OpenAI Finetuning • ButtondownTwitterTwitter
Chapters
AI Twitter & Reddit Recaps
High-Level Discord Summaries
Future AI Innovations and Discussions
Various AI Discord Channels Highlights
OpenAI Discussions
Model Troubleshooting and Updates
Neural Reasoning and Command R+ Model Introduction
Discussion on Modular (Mojo 🔥) Discord Channels
Autogen Studio Issues and Solutions
Research Innovations in Efficient Model Architectures
Use of Tool for Complex Tasks
HuggingFace and OpenRouter Discussions
Interconnects
LangChain AI Community Updates
Discussions on AI Research and Development
AI Twitter & Reddit Recaps
The AI Twitter and Reddit Recap section covers recent updates and releases in the AI community. Highlights include the release of Coher Command R+ and DALL-E 3 Inpainting features. It also discusses the advancements in model capabilities, AI research, and education. The section showcases tools like GPT-4 Vision, automatic video highlight detection, and Daz3D AI-Powered Image Generation. Additionally, it explores AI memes and humor shared on social media platforms. The summary provides insights on the latest features and integrations of AI models like Command R+ and DALL-E 3, emphasizing their multilingual support, pricing, and availability. Furthermore, it includes discussions on Mixture-of-Depths for efficient transformers and Stanford's Transformers Course opening to the public.
High-Level Discord Summaries
AI Discord Recap
- Adaptive RAG techniques: New papers propose dynamically selecting RAG strategies based on query complexity. Examples include LangChain and LlamaIndex cookbooks.
- RAG-powered applications: Examples of RAG-powered apps include Omnivore, an AI-enabled knowledge base, and Elicit's task decomposition architecture.
- Open-Source Models and Frameworks: Open models include Yi from 01.AI, Eurus from Tsinghua, Jamba from AI21 Labs, and Universal-1 from AssemblyAI. Efficient inference techniques like BitMat, Mixture-of-Depths, HippoAttention, and MoE optimizations are introduced. Accessible model deployment options by Hugging Face, Koyeb, and SkyPilot are also highlighted.
Memes and Humor
- An AI-generated video of a sad girl singing the MIT License went viral.
- Speculations about Apple's AI ambitions and jokes about AI replacing software engineers were shared.
- Memes poking fun at AI hype and the limitations of large language models were popular.
Future AI Innovations and Discussions
The section delves into various future AI innovations and ongoing discussions within specialized Discord communities. It includes exciting developments such as Mojo's integration with ROS 2 for robotics applications, significant library performance improvements, and the introduction of BlazeSeq for FASTQ parsing in the Mojo ecosystem. Moreover, it highlights the potential of LM Studio's local embedding models and the robustness brought by models like Mixtral and VAR in image generation. The discourse also covers skepticism around efficiency claims in AI algorithms, infrastructure innovations like SaladCloud for AI/ML workloads, and the unveiling of a behemoth 104 billion parameter C4AI Command R+ model. The section also touches on AI model behavior debugging, financial challenges facing AI innovators, and the potential optimizations with dynamic FLOP allocation in transformers.
Various AI Discord Channels Highlights
- Mozilla AI: Highlights include discussions on matrix optimization, compiler enhancements, and requirements for successful deployments.
- LangChain AI: Topics covered include crypto chatbot development, math symbol extraction techniques, and voice applications powered by innovative technologies.
- CUDA MODE: Discussions revolve around efficient implementation of language models, new visualizer features, and recommendations for learning CUDA programming.
- Datasette - LLM (@SimonW): Conversations focus on AI dialogue terminology, AI evaluation strategies, and detailed API responses provided by Cohere LLM search API.
- DiscoResearch: Topics include benchmarking emotional intelligence, AI model evaluations, and the integration of different models for translation tasks.
- Skunkworks AI: Discussions touch on AI applications in healthcare, innovative techniques like Mixture-of-Depths (MoD), and strategies for AI to solve mathematical problems efficiently.
OpenAI Discussions
This section includes various discussions happening in different channels related to OpenAI, such as debating the impact of Fritz Haber, exploring the LLM Leaderboard, understanding beauty through AI, discussing the emergence of dictatorship, and ensuring shareable content on Discord. The conversations delve into topics like AI's consciousness, defining sentience, AI misconceptions, and potential AI usage ideas. Members also discuss model performance, AI role-playing, and practical applications like utilizing AI for Wiki data. Technical discussions encompass translation troubles, prompt engineering queries, and challenges faced in text generation, as well as job postings, ethical considerations in hiring, and performance inquiries about innovations in Unsloth AI.
Model Troubleshooting and Updates
Tokenizer Troubles
- User faced error due to incorrect naming of model in tokenizer, which affected writing and execution.
Successful Model Saving and Huggingface Push
- Users discussed saving models with
model.save_pretrained_merged()andmodel.push_to_hub_merged(), focusing on setting naming parameters and obtaining Write token.
Inference Issues on Gemma
- User faced
AttributeErrorwithGemmaForCausalLMobject, fixed by updating Unsloth package.
Challenges with GGUF Conversions and Docker Environments
- Users shared conversion issues to GGUF format and Docker environment error solved with
python3.10-devinstallation.
Finetuning Challenges and Solutions
- Discussion on Gemma model finetuning, remedies for
OutOfMemoryError, GGUF-spelled words quirk, and insights on resuming training with altered parameters.
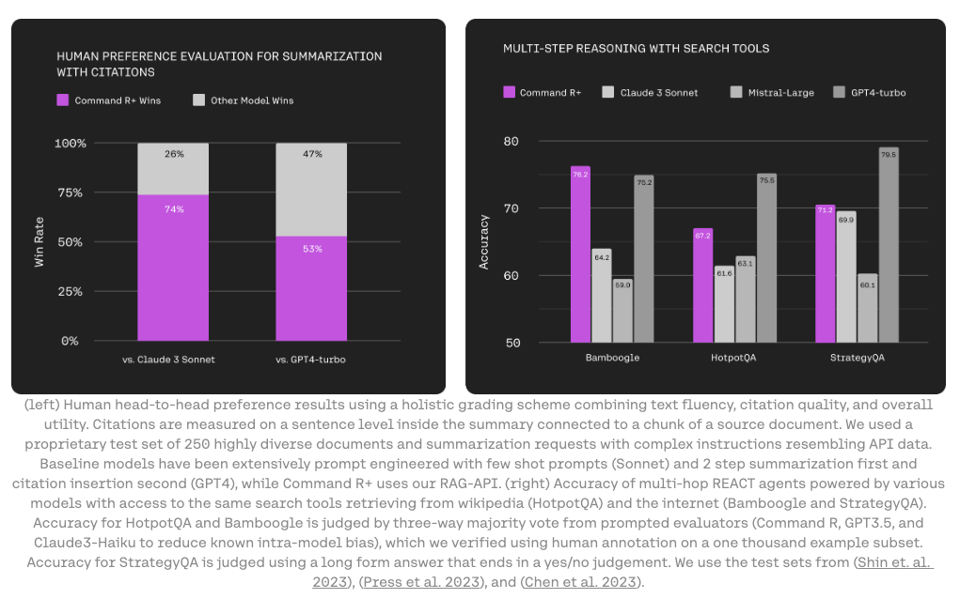
Neural Reasoning and Command R+ Model Introduction
The section discusses experiments with language model pruning, dynamic compute allocation for LLMs, speculative decoding techniques, and the introduction of Cohere's Command R+ model optimized for Retrieval Augmented Generation (RAG). Additionally, it explores projects like the neurallambda Github repository integrating lambda calculus with LLMs for AI reasoning and Glaive's dataset creation for RAG applications. Members converse about grounded mode in RAG, proper citation markup, and potential uses of RAG combined with function calling. The Cohere RAG documentation is highlighted, along with discussions on synthetic data generation possibilities.
Discussion on Modular (Mojo 🔥) Discord Channels
WorldSim Discussions:
- Members discuss copy-pasting difficulties on Desktop compared to Mobile, noting challenges with HTML code wrapping. One member created a python program for 'paste' but faced initial website issues.
- Concerns raised about WorldSim website slowdown on mobile, recommend reloading from a save. Original WorldSim noted for best performance despite lacking quality-of-life features.
- System prompt for WorldSim shared publicly through Twitter post, and an easier-to-copy version posted on Pastebin.
- Updated WorldSim Command Index shared, prompting discussion on advanced commands and 'sublimate' command for dismissing persona entities.
- Users attempt to bypass prompts using Claude models, report success on labs.perplexity.ai. ASCII art inquiry revealed to represent the Nous girl logo.
Discussions on Modular (Mojo 🔥) General Channel:
- User shares example of GitHub workflow for modular auth and Mojo packaging. Link inaccessible but followed up with copy-pasted snippet.
- Inquiry made on debugger and LSP availability beyond VSCode, highlighting neovim.
- Discord solution offered to a user's problem but with an incomplete link to the solution.
- Notification raised on lack of Modular Community Livestream alert, link provided discussing 'New in MAX 24.2'.
- Request shared for Mojo completion roadmap and comparison with Taichi or Triton, addressed by sharing Mojo development roadmap link.
Integration of Mojo with ROS 2 in the AI Channel:
- Proposal to integrate Mojo with ROS 2 for bug mitigation, highlighting Rust support. Discussion on Python's predominance in ROS 2 community and transition to C++ for performance.
- Potential for Mojo leveraging Nvidia Jetson hardware due to limitations with Python GIL causing performance issues.
Community Projects Channel Updates:
- Logger library updated for logging messages, and BlazeSeq published as a FASTQ parser. Buffered Line Iterator implemented for improved file handling.
Performance and Benchmarks Discussions:
- Community engagement milestone celebrated. User reports performance gains using a library. Shell script shared for library installation ease.
- Tips suggested for library optimization, mention of potential sorting algorithm update.
Mojo🔥 Newsletter Highlights:
- Release of Max⚡ and Mojo🔥 24.2 announced with open-sourcing of standard library and nightly builds launch. Community engagement noted with pull requests.
- Mojo🔥 open-source initiative detailed in a blog post.
- Mojo🔥 24.2 release features enhanced Python interoperability discussed.
- Invitation to explore Higher Order Functions in Mojo🔥 with teaser link provided on Twitter.
Autogen Studio Issues and Solutions
A member reported receiving truncated outputs with Autogen Studio in LM Studio, seeking a solution for complete completion results. In another channel, members discuss maintaining 'memory' retention in the same runtime, highlighting challenges in preserving state across interactions with the bot.
Research Innovations in Efficient Model Architectures
A new approach called T-GATE suggests that cross-attention in text-to-image diffusion models may be unnecessary after understanding the coarse semantics of an image, potentially speeding up the process. However, the effectiveness of T-GATE has not been fully convincing to the community. Another breakthrough references potential hardware improvements like the FFIP algorithm, claiming significant efficiency gains by reducing half the multiplications for cheap additions. Moreover, a recent arXiv paper introduces a method for transformers to dynamically allocate compute across a sequence, optimizing performance and allowing for a pre-defined compute budget. This diverges from uniform FLOP distribution, proposing a more selective and potentially efficient allocation of resources. Additionally, discussions on Huge Scale Language Models (HLB-GPT) explore follow-ups to Mixture of Experts (MoE) work and specific design choices, dedicating a thread for detailed exchange without cluttering the main channel. Finally, discourse surfaced on the challenges and potential violations associated with scraping platforms like Discord, where theoretically feasible data crawling breaches Terms of Service and can lead to account bans.
Use of Tool for Complex Tasks
In this section, discussions revolve around the cost concerns of running large models for complex tasks. Various links mentioned include resources for GPU cloud, and toolkits for transformer models. In the OpenAccess AI Collective chats, issues like GitHub bug fixes, table of contents mismatches, and fine-tuning strategies are tackled. Additionally, there are conversations about dataset recommendations, fine-tuning techniques, and the deployment of models with UI feedback. The Axolotl Discord channels address topics such as fine-tuning practices, multi-node fine-tuning with Docker, and issues with checkpoints and mixed precision. Members also encounter downtime with the Axolotl bot. Lastly, LlamaIndex chats cover topics including exploring limitations in querying knowledge graphs, seeking recursive query engine docs, and discussions on LlamaIndex agents handling and implementation issues.
HuggingFace and OpenRouter Discussions
This section covers various discussions and updates within the HuggingFace and OpenRouter communities. Users discussed topics such as seeking AI for game testing, fine-tuning access control for enterprise repositories, and troubleshooting multi-GPU system setups. There were also conversations about deploying and using HuggingFace models, advice on fine-tuning image generation models, and exploring the balance between speed and smartness in production prompts. Additionally, the section highlights discussions on diffusion transformers, including customized models for stereo-to-depth map conversion and alternative approaches for depth estimation. The content also features interactions related to tinygrad development, such as performance ambitions, technical details on GPU and NPU kernel drivers, and collaborative efforts in biofield technology. Lastly, the OpenRouter channel touched on clarifying support for 'json_object' response format in models like OpenAI and Fireworks endpoints.
Interconnects
OpenInterpreter
- A member successfully installed software on a Windows PC and shared their experience.
- Discussion about troubleshooting Termux issues.
- Advice to move detailed technical support topics to appropriate channels.
- Exchange of mutual encouragement regarding posting in the community and learning experiences.
- Clarifications on software compatibility and install instructions.
O1
- Discussion on best practices for Hermes-2-Pro models.
- User facing challenges with the verbose output in O1 server.
- Troubleshooting Linux complications with O1 software.
- Issues encountered when using poetry on Windows 11.
- Development discussions on using the M5 Cardputer for the open-interpreter project.
ml-drama
- Nathan Lambert hints at potential controversy in a tweet.
- Discussion and challenges surrounding the effectiveness of ChatGPT-like models for business applications.
- Teaser for an upcoming article critiquing current models.
random
- Sharing Financial Times subscription offer for access to quality journalism.
- Concerns raised about traditional business models inhibiting the success of 'genAI'.
- Lukewarm reception to a tech politics discussion by notable figures.
- Details shared about Stanford's CS25 course attracting AI enthusiasts.
llamafile
- Member discussion on improving a matmul kernel for efficiency.
- Celebrations on achieving compiler magic for code transformation.
- Requirements for ROCm version on Windows for llamafile-0.7.
- Conversations on handling SYCL code in llamafile and issues with Cosmopolitan compiler on Windows.
- Attempts to build llamafile on Windows and the need for performance benchmarking.
general
- User seeking experienced developers for building a human-like chatbot with a real-time database.
- Inquiry about alternatives to MathpixPDFLoader for extracting math symbols from PDFs.
- Search for a community manager or developer advocate at LangChain.
- Guidance sought on creating a bot in JavaScript that schedules appointments and interacts with a database.
- Discussion on the '|' operator in LCEL and its use in chaining components like prompts and llm outputs.
LangChain AI Community Updates
The LangChain AI community has been active with various discussions and updates. In one exchange, users reported trouble with agents searching PDFs and sought advice. Another user announced the launch of multiple voice apps, including CallStar, CallJesus, and CallPDF. AllMind AI, a financial analysis-focused LLM, was introduced alongside Galaxy AI's free premium API service featuring GPT-4 and Gemini-PRO. In another section, users shared insights on CUDA programming and torch benchmarking issues. Additionally, the community delved into Triton Visualizer collaboration and Lightning Attention Sequence Parallelism. The discussion also covered topics like repeatability in science, CUDA learning paths, and integrating HQQ with GPT-fast. Finally, emotional intelligence benchmarks, creative writing evaluations, and fine-tuning rating scales were explored in the DiscoResearch channel.
Discussions on AI Research and Development
DiscoResearch ▷ #discolm_german
-
COMET Scores Unveiled: A member shared COMET scores demonstrating the performance of various language models. The highest score was 0.848375 for a file named Capybara_de_wmt21_scored.jsonl.
-
Reference-Free Evaluation: The mentioned scores are reference-free COMET scores, specifically using wmt22-cometkiwi-da. Resources and scripts related to the evaluation were provided at llm_translation on GitHub.
-
Accuracy Caveats: The results posted are indicative, and potential inaccuracies may occur.
Skunkworks AI ▷ #general
-
AI in Healthcare Gains Another Voice: A participant discussed involvement in the AI medical field, highlighting the increasing community members in healthcare tech.
-
Innovating LLMs with Mixture-of-Depths (MoD): A new approach called Mixture-of-Depths (MoD) was introduced, allowing Language Models to allocate compute dynamically. The paper and abstract are accessible via the PDF on arXiv.
Skunkworks AI ▷ #finetuning
- Decomposition Strategy for Math Problems: A member suggested training AI to break down math word problems into equations for external solving using tools like Python or Wolfram Alpha.
Skunkworks AI ▷ #papers
- carterl shared a link to an arXiv document.
Alignment Lab AI ▷ #general-chat
- jinastico mentioned a user.
FAQ
Q: What are some recent updates and releases in the AI community mentioned in the essay?
A: Recent updates and releases in the AI community include Coher Command R+, DALL-E 3 Inpainting, GPT-4 Vision, automatic video highlight detection, Daz3D AI-Powered Image Generation, and advancements in model capabilities, AI research, and education.
Q: What are some tools and applications powered by RAG techniques discussed in the AI Discord Recap?
A: Some tools and applications powered by RAG techniques discussed in the AI Discord Recap include LangChain and LlamaIndex cookbooks, Omnivore AI-enabled knowledge base, and Elicit's task decomposition architecture.
Q: What are some open-source models and frameworks highlighted in the AI Discord Recap?
A: Open-source models and frameworks highlighted in the AI Discord Recap include Yi from 01.AI, Eurus from Tsinghua, Jamba from AI21 Labs, Universal-1 from AssemblyAI, BitMat, Mixture-of-Depths, HippoAttention, MoE optimizations, and model deployment options by Hugging Face, Koyeb, and SkyPilot.
Q: What are some popular AI memes and humor shared on social media platforms?
A: Some popular AI memes and humor shared on social media platforms include an AI-generated video of a sad girl singing the MIT License, speculations about Apple's AI ambitions, jokes about AI replacing software engineers, and memes poking fun at AI hype and large language models' limitations.
Q: What are some future AI innovations and ongoing discussions highlighted in the essay?
A: Future AI innovations and ongoing discussions include Mojo's integration with ROS 2 for robotics applications, library performance improvements, BlazeSeq for FASTQ parsing, LM Studio's local embedding models, the Mixtral and VAR models in image generation, skepticism around efficiency claims in AI algorithms, infrastructure innovations like SaladCloud, and the unveiling of a 104 billion parameter C4AI Command R+ model.
Q: What are some challenges and solutions discussed regarding model saving and inference issues?
A: Challenges and solutions discussed include model saving with `model.save_pretrained_merged()` and `model.push_to_hub_merged()`, inference issues on Gemma with `AttributeError`, challenges with GGUF conversions and Docker environments, and finetuning challenges like `OutOfMemoryError` and GGUF-spelled words quirk.
Q: What are some discussions and developments in AI models and techniques outlined in the essay?
A: Discussions and developments include experiments with language model pruning, dynamic compute allocation for LLMs, speculative decoding techniques, the Cohere Command R+ model optimized for RAG, integration of lambda calculus with LLMs for AI reasoning, T-GATE approach for text-to-image diffusion models, FFIP algorithm for hardware improvements, and dynamic FLOP allocation in transformers.
Q: What are some topics covered in the WorldSim discussions highlighted in the essay?
A: Topics covered in WorldSim discussions include copy-pasting difficulties on Desktop and Mobile, concerns about WorldSim website slowdown, shared system prompts, WorldSim Command Index, bypassing prompts with Claude models, and ASCII art representation inquiries.
Q: What are some community projects updates and performance discussions mentioned in the essay?
A: Community projects updates include the Logger library for logging messages and BlazeSeq as a FASTQ parser, as well as benchmark celebrations, library optimization tips, and Mojo🔥 Newsletter highlights. Performance discussions cover wins using a library, suggestions for optimization, and tips for library installation ease.
Q: What are some discussions in the OpenInterpreter channel as outlined in the essay?
A: Discussions in the OpenInterpreter channel include successful software installations on Windows PC, troubleshooting Termux issues, mutual encouragement in the community, and clarifications on software compatibility and installation instructions.
Q: What are some developments and topics discussed in the LangChain AI community highlighted in the essay?
A: Developments and topics discussed in the LangChain AI community include trouble with agents searching PDFs, multiple voice apps launch, AllMind AI introduction, CUDA programming insights, torch benchmarking issues, Triton Visualizer collaboration, Lightning Attention Sequence Parallelism, and repeatability in science.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!