[AINews] CodeLLama 70B beats GPT4 on HumanEval • ButtondownTwitterTwitter
Chapters
High-level Discord Summaries
LLM Perf Enthusiasts AI Discord
Coding and GitHub Navigation
Breakthrough in LLM Context Length with Activation Beacon
Discussion on LM Studio Hardware and Model Performance
Mistral La Plateforme
AI Community Conversations
HuggingFace DiscoResearch Discussions
Defining Hard Negatives and Training Prompts
Advancements in AI Model Training and Storage Solutions
Datasette - LLM (@SimonW)
High-level Discord Summaries
This section provides a summary of high-level Discord discussions from TheBloke, Nous Research AI, LM Studio, OpenAI, and OpenAccess AI Collective (axolotl). Some highlighted topics include debates on the Miqu model, discussions on the Aphrodite engine's performance, advancements in LLM context length with the Activation Beacon project, performances of models like Eagle-7B and OpenHermes2.5, and exploration into multimodal models. Users also shared insights on GPU choices, model compatibility updates, and performance issues in LM Studio. In addition, Prompt engineering techniques, AI ethics considerations, and limitations of GPT-4 were discussed within the community. Lastly, innovations like SmoothQuant for LLM throughput enhancement and challenges of integrating new technologies into existing systems were explored.
LLM Perf Enthusiasts AI Discord
- Triton: Balancing Control and Complexity:
@tvi_noted thatTritonstrikes a balance for AI engineers, offering more control thanPyTorchand less complexity than directCUDA, catering to efficiency seekers without the need for deep CUDA knowledge. - An Odyssey of CUDA Optimization for RGB to Grayscale: In efforts to optimize
RGB to Grayscale conversion,@artste...`
Coding and GitHub Navigation
Users in the #coding channel discussed various topics related to coding and GitHub navigation. Some highlights include:
- Navigating GitHub Projects: Tips were shared on understanding the structure of GitHub projects for contributing, with emphasis on finding the entry point like the
start.pyfile. - Entry Points in Python: The concept of entry points in Python projects, indicated by the
if __name__ == "__main__", was clarified for better code exploration. - Importance of IDEs and Editors: The importance of using IDEs or editors with language servers for efficient code navigation, along with mentioning tools like Sourcegraph's VSCode extension and GitHub's search features.
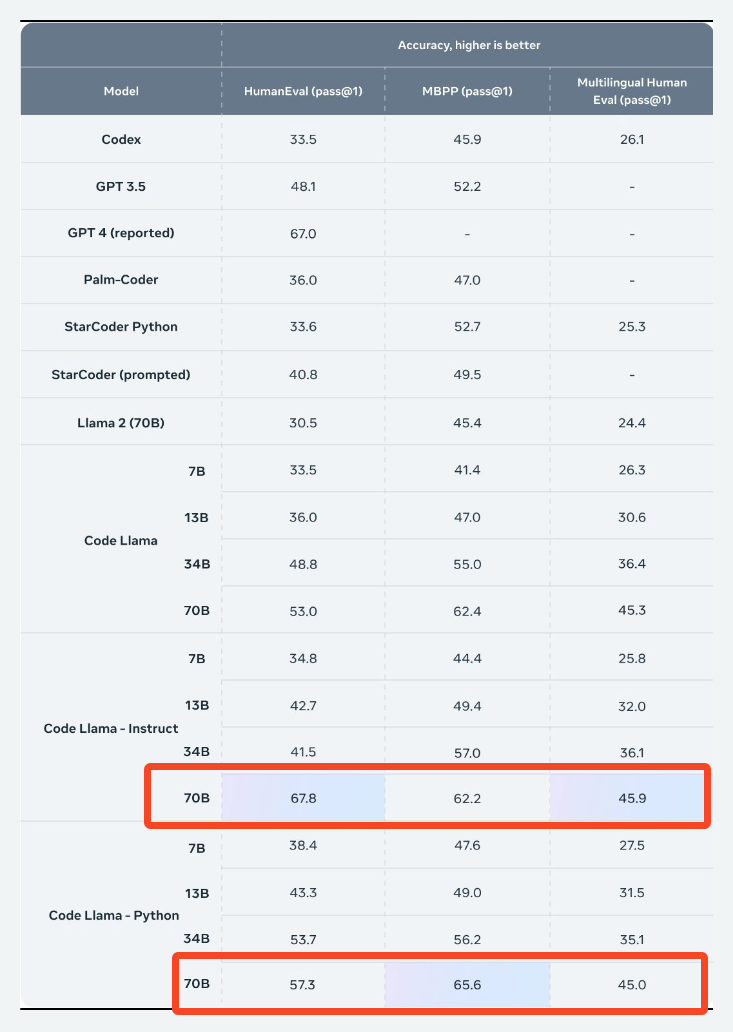
- New AI Model: The release of the Code Llama 70B model on Hugging Face, specialized in code generation and debugging across programming languages, was announced.
- Reading Source Code: The underrated skill of reading source code effectively was discussed, with suggestions on making educated guesses and a potential demo of Cody for assistance.
Breakthrough in LLM Context Length with Activation Beacon
- Significant Development: The Activation Beacon technique allows for unlimited context length in LLMs by introducing 'global state' tokens.
- Generalization Achievement: Demonstrated with LLaMA 2, it can generalize from 4K to 400K context length.
- Issue Resolution: This breakthrough could potentially 'solve' context length limits if reproducible across other models.
- Further Exploration: Accompanied by a paper and code link for deeper investigation.
Discussion on LM Studio Hardware and Model Performance
This section covers various discussions related to hardware recommendations for running Large Language Models (LLMs), compatibility issues, model format clarifications, and techniques for optimizing model performance in LM Studio. Users share insights on GPU choices, running LLMs on CPUs, and troubleshooting issues related to VRAM overhead and memory usage. Additionally, there are conversations on the utilization of integrated GPUs, upcoming GPU releases, and stability concerns with certain model versions. The section also includes discussions on selecting the right model for specific tasks, exploring multimodal models, and addressing performance lag and navigational challenges within the LM Studio user interface.
Mistral La Plateforme
Mistral API Rate Limits Express Concern:
- User @arnaud_35886 queried about the maximum rate limit for using Mistral APIs in production, indicating a need greater than the current offering. Initial confusion about the nature of the limit (rate vs cost) was clarified. Approval for rate limit increases typically depends on usage history, starting at 2 requests/second.
Token and Embedding Limits Under Scrutiny:
- User @dierkdroth sought clarification on token limits for Mistral API text embeddings and received a mix of direct and inferred answers. @sophiamyang confirmed the max token limit to be 32k for tiny/small/medium models and 8192 for the embedding API.
Explorations in Mistral's Tokenization:
- In pursuit of details regarding the tokenizer used by Mistral's models, @dierkdroth inquired about the specific tokenizer and referenced a JavaScript implementation. @sophiamyang acknowledged the lack of documentation and promised an update, whereas @vhariational compared it to tokenizers found in HuggingFace repositories.
Java Client Integration Proposal:
- User @carloszela proposed adding a new client for Java users to the official Mistral documentation, showcasing an ongoing project on GitHub named langchain4j supporting Mistral AI models.
Awaiting Fixes for Early Stopping Issue:
- User @digitalphotographer followed up on a previously reported issue regarding early stopping behavior in Mistral's platform, looking for updates after sending notebooks for reproduction of the error to @sophiamyang and another.
AI Community Conversations
The Eleuther channel discussed new AI research papers, criticism of AI regulation fact sheets, exclusion of NIST AISI, skepticism over taskforces, and concerns about AI/ML education in schools. The HuggingFace channel conversations included community guidelines on PR tagging, patience for PR reviews, exploring continuous neural network processes, success of a deepfake detection pipeline, and discussions on Fedora versus Ubuntu for machine learning on AMD hardware. Additional discussions covered deep learning breakthroughs in medical imaging, innovative AI model demos, resume question answering space, Mistral on Apple Silicon video performance, and a challenging ABSA model creation for laptop reviews.
HuggingFace DiscoResearch Discussions
- MIQU Model Sparks Mixtral Medium Leak Speculation: A conversation around the MIQU model possibly being a Mixtral medium leak, discussing its characteristics and origins.
- Debunking the MIQU Model-Mixtral Connection: Swiftly addressing rumors about the MIQU model and Mixtral connection, clarifying that these rumors were already debunked.
- Clarification Tweet from Nisten: Sharing a tweet from Nisten to further debunk rumors about the MIQU model.
- MIQU Model and LLaMA Tokenizer Connection Highlighted: Highlighting the usage of a LLaMA tokenizer in the MIQU model, along with sharing relevant tweets for more details.
Defining Hard Negatives and Training Prompts
A considerable amount of discussion focused on creating high-quality 'hard negatives' for training data. @sebastian.bodza and @philipmay debated the criteria, with emphasis on the importance of hard negatives not answering the question directly to prevent training issues. Additionally, @sebastian.bodza iteratively improved the prompts used for generating training data, aiming to fine-tune the balance between positive examples and hard negatives driven by feedback and the quest for optimally structured data sets. Clarity was sought regarding the purpose and structure of datasets for DPR and RAG training, particularly about context and the kind of hard negatives. @sebastian.bodza clarified that their work aims to generate a passage retrieval dataset for future RAG use, with examples varying in quality rather than content relevance.
Advancements in AI Model Training and Storage Solutions
Several advancements and discussions were highlighted in this section. Noteworthy findings include the remarkable results of training an LLaMA 2 model for extended context lengths, the debate on optimal storage methods for captioned image datasets using parquet files or tar files, and the advantages of using webdatasets for high-performance Python-based I/O systems. Additionally, inquiries were made about the optimal usage of AI models, the feasibility of querying Perplexity via URL parameters, and the exploration of latent diffusion in RePaint. Practical solutions were suggested for topics such as combining parquet and TAR for efficient data management and the implementation of custom Stop Words in the pplx-api for enhanced functionality.
Datasette - LLM (@SimonW)
Emoji Suggestion Tool Unveiled:
- @dbreunig showcased a new demo at Emoji Suggest that can convert short sentences or headlines into a single, recommended emoji using the CLIP model. The code for the tool is available.
Insights on Embeddings for Search Applications:
- @dbreunig shared insights on using embeddings to create sophisticated search tools quickly.
AI's Positive Perspective on its Role:
- @bdexter relayed a conversation where an AI expressed the belief that artificial intelligence is a force for good.
ColBERT Writeup Appreciation:
- User @bewilderbeest expressed gratitude towards @746595581086138409 for the ColBERT writeup on TIL.
Is GPT-5 Training Underway?:
- User @entropi shared a YouTube video titled 'GPT-5: Everything You Need to Know So Far'.
Confirmation on GPT-5 Training:
- In response to speculation, @lightningralf confirmed that GPT-5 has been in training for some time.
FAQ
Q: What are some highlighted topics discussed in the Discord community involving TheBloke, Nous Research AI, LM Studio, OpenAI, and OpenAccess AI Collective?
A: Some highlighted topics include debates on the Miqu model, discussions on the Aphrodite engine's performance, advancements in LLM context length with the Activation Beacon project, performances of models like Eagle-7B and OpenHermes2.5, and exploration into multimodal models.
Q: What is the Triton software noted for in the AI engineering community?
A: `Triton` strikes a balance for AI engineers, offering more control than `PyTorch` and less complexity than direct `CUDA`, catering to efficiency seekers without the need for deep CUDA knowledge.
Q: What significant development does the Activation Beacon technique bring to Large Language Models (LLMs)?
A: The Activation Beacon technique allows for unlimited context length in LLMs by introducing 'global state' tokens, enabling a breakthrough in extending context length limits.
Q: What were some concerns expressed regarding hardware recommendations for running LLMs in LM Studio?
A: Discussions covered hardware recommendations, compatibility issues, model format clarifications, and techniques for optimizing model performance. Users shared insights on GPU choices, VRAM overhead, memory usage, navigating challenges within the LM Studio UI, and stability concerns with certain model versions.
Q: What were the discussions revolving around Mistral API in the Discord community?
A: Discussions encompassed concerns about Mistral API rate limits, token and embedding limits, details on Mistral's tokenization process, proposals for Java client integration, and the status of fixes for early stopping issues within the Mistral platform.
Q: What notable conversations were held around the MIQU model in Discord?
A: Conversations covered speculation on the MIQU model's connection with Mixtral, debunking rumors about this connection, highlighting the MIQU model's tokenizer connection, and sharing relevant tweets to provide more insights.
Q: What advancements and discussions were highlighted in the section regarding 'hard negatives' for training data?
A: Discussions focused on creating high-quality 'hard negatives' for training data, with criteria debated by users to prevent direct answers, emphasizing the importance of balanced datasets in generating optimal training examples.
Q: What was showcased in the Emoji Suggestion Tool unveiled section?
A: A new demo called Emoji Suggest that converts short sentences or headlines into a single recommended emoji using the CLIP model was showcased, along with insights on using embeddings for search applications and discussions on AI's positive role.
Q: Is GPT-5 training currently underway?
A: Speculation regarding GPT-5 training was confirmed with discussions indicating that GPT-5 has been undergoing training for some time.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!