[AINews] Claude Crushes Code - 92% HumanEval and Claude.ai Artifacts • ButtondownCommitters Channel SummaryTwitterTwitter
Chapters
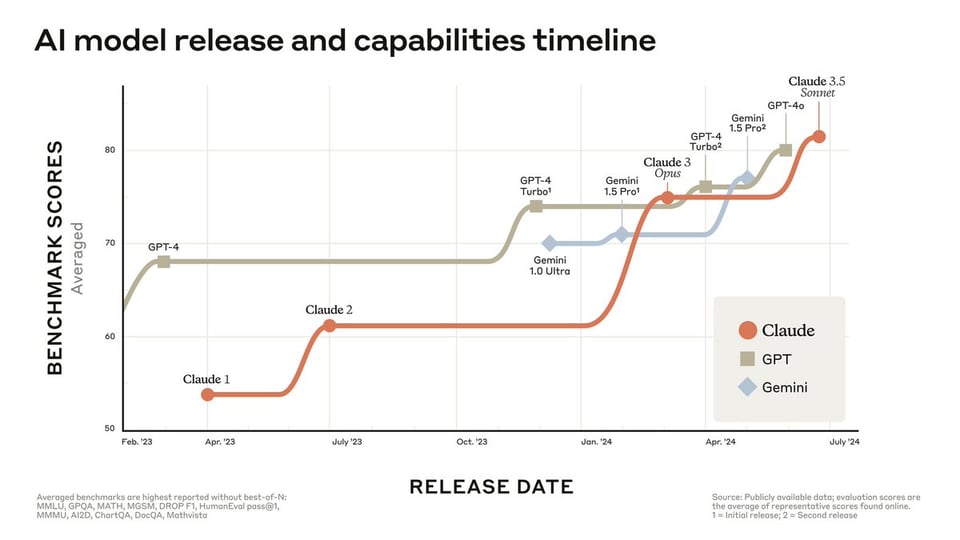
Claude 3.5 Sonnet Release by Anthropic
AI Benchmarks and Evaluations
Perplexity AI Discord
LlamaIndex Discord
Discussion on Self-Development Platforms
Perplexity AI, CUDA MODE, and LLM Discussion Highlights
CUDA MODE and FPx Kernels
Florence-2 Model Impresses Users
AI Stack Devs (Yoko Li) - Recent Channel Activities
LM Studio - General Chat
Interconnects: OpenAccess AI Collective (axolotl) General
Chatbot Development and Technical Discussions
Accounts Assistance and Account Credits Issues
Social Networks and Footer
Claude 3.5 Sonnet Release by Anthropic
The release of Claude 3.5 Sonnet by Anthropic introduces performance improvements, surpassing competitor models in key evaluations. It operates at twice the speed of Claude 3 Opus and is highlighted for its coding abilities. The model card showcases enhanced context utilization, and the addition of 'Artifacts' feature allows users to interact with AI-generated content in real-time, similar to OpenAI's Code Interpreter or Cognition Labs' Devin.
AI Benchmarks and Evaluations
The section discusses various advancements and developments in the field of AI, including the introduction of new AI models such as MoA and Infinity Instruct. These models have shown enhanced performance compared to existing benchmarks like GPT-4. Additionally, there are discussions on open-source initiatives, collaborations, and strategies for model optimization and training. Memes and humor related to the AI industry are also highlighted, showcasing a lighthearted take on recent developments and trends.
Perplexity AI Discord
In the Perplexity AI Discord section, various discussions and developments are highlighted. The CEO of Perplexity engages in a podcast discussing AI impact on search, while users report technical issues and anticipations for upgrades. The topic of AI ethics sparks debates, and conversations range from career paths to psychedelic experiences. The Perplexity API's performance and limitations are also reviewed. In parallel, the CUDA MODE Discord section covers topics like INT8 optimization, kernel profiling, and AI breakthroughs. Models like Qwen2 and DiscoPOP are discussed for their potential in boosting LLM performance. Optimization techniques like quantization and new technologies like the H100 box for speed improvements are explored. The section concludes with updates on modular Mojo Discord, Nous Research AI Discord, Eleuther Discord, LM Studio Discord, OpenRouter Discord, AI Stack Devs Discord, and Interconnects Discord.
LlamaIndex Discord
- CrewAI teams up with LlamaIndex to enhance multi-agent systems for defining crews leveraging LlamaIndex capabilities.
- LlamaIndex founder to present at AI Engineer's World's Fair on the future of Knowledge Assistants, with major announcements on June 26th and June 27th.
- Engineers exploring the flexibility of LlamaIndex's VectorStoreIndex and generating questions from PDFs using DatasetGenerator.
- Tutorial on persisting indexes in LlamaIndex and utilizing storage_context.persist() for storing DocumentSummaryIndex.
Discussion on Self-Development Platforms
Users engage in a conversation about the top three self-development platforms, focusing on Mindvalley and courses like 'Unlimited Abundance' and 'Superbrain' by Jim Kwik. These courses cover topics such as mindfulness, health, and personal growth. The discussion highlights the popularity and content offered by these platforms.
Perplexity AI, CUDA MODE, and LLM Discussion Highlights
The latest updates include a survey on psychedelics and God encounters, high-paying jobs for English literature majors, Lululemon earnings speculation, and more. In the tech discussions, Perplexity API limitations, using Triton with Nsight Compute, and resetting API keys were highlighted. Other discussions covered AI advancements like Character.AI's efficient Int8 training and AI Unplugged covering trends like Qwen2 and DiscoPOP. In the CUDA MODE channels, members shared insights on various topics including optimizing CUDA kernels with Nsight Compute, deploying Triton 3.0.0, and exploring advanced quantum methods. Job opportunities for ML engineers at Nous Research were also mentioned, along with user tips on enhancing productivity with native files apps and alternative mirroring solutions. To sum up, these threads offer a diverse range of discussions on tech advancements, job opportunities, AI trends, and CUDA-related topics.
CUDA MODE and FPx Kernels
CUDA MODE ▷ #bitnet (22 messages🔥):
- The new FPx kernel from FP6-LLM can perform FP16 operations with FPx for x ranging from 1 to 7, though FP1 and FP2 are less practical. Limitations include lack of support for group-wise quantization. Benchmarks for different quantization methods on wikitext show varied perplexity and token speeds. Ongoing work to develop an end-to-end test case for uint2 quantization and ongoing benchmarking tasks. Using FPx-LLM kernel, FP2 and FP4 multiplications show speedups ranging from 3.77x to 10.64x over FP16 multiplications, depending on matrix sizes. Discussion on challenges in implementing fp16 -> fp8 conversions, noting potential slowdowns despite hardware instructions availability.
Links mentioned:
- ao/torchao/prototype/fp6_llm/fp6_llm.py at fp5_llm · gau-nernst/ao: Native PyTorch library for quantization and sparsity.
- ao/torchao/csrc/cuda/fp6_llm/utils_parallel_dequant.cuh at fp5_llm · gau-nernst/ao: Native PyTorch library for quantization and sparsity.
- fp6_llm/fp6_llm/csrc/fp6_linear.cu at 5df6737cca32f604e957e3f63f03ccc2e4d1df0d · usyd-fsalab/fp6_llm: Efficient GPU support for LLM inference with x-bit quantization (e.g., FP6,FP5) - usyd-fsalab/fp6_llm.
- fp6_llm/fp6_llm/csrc/include/utils_parallel_dequant.cuh at 5df6737cca32f604e957e3f63f03ccc2e4d1df0d · usyd-fsalab/fp6_llm: Efficient GPU support for LLM inference with x-bit quantization (e.g., FP6,FP5) - usyd-fsalab/fp6_llm.
Florence-2 Model Impresses Users
The Florence-2 large model from Microsoft impressed users with its versatility and efficiency, supporting tasks like captioning, OCR, and object detection despite its smaller size. Conversations highlighted its potential use in low-power devices like Raspberry Pi and its comparison to other models like DINOv2.
AI Stack Devs (Yoko Li) - Recent Channel Activities
- Spam Alert in Discord Channel: Multiple messages promoting inappropriate content were posted, including mentions of '18+ Free Content' and OnlyFans leaks. Discord links were included in each message, leading to potential spam and explicit material.
- Bot Activity Concern: Users reported and took action against a bot named 'bot1198' that repeatedly shared links to '18+ Free Content' and OnlyFans leaks, causing disturbance in the channel.
- Flood of Spam Invites: Multiple instances of users sharing links to '18+ Free Content' and sexcam video calls were observed, along with repeated invitations to join a specific Discord server.
LM Studio - General Chat
Members of the LM Studio general chat discussed various topics related to LM Studio and AI technologies:
- Some users reported speed improvements with LM Studio version 0.2.23 and challenges with Deepseek Coder v2.
- There were discussions on exploring frontend options for LLM servers, frustrations with Reddit censorship, and considerations on NVLink and memory for GPU upgrades.
- Users shared experiences with different models like Midnight Miqu and Opus, as well as issues with DeepSeek Coder V2 Lite defaulting to Chinese responses.
- Users also debated GPU choices for LLMs, including the benefits of waiting for new models like the 5090 or opting for refurbished ones.
- In hardware discussions, recommendations were made for specs needed to run large models like Nemotron-4-340B and Meta-Llama-3-70B-Instruct.
- Issues were raised regarding GPU detection, offloading, and acceleration for models on Linux Mint and M1 Mac.
- Additionally, users discussed challenges faced with DeepseekV2 models in LM Studio, suggested solutions for GPU issues, and shared experiences converting code to use different backends and pipelines.
Interconnects: OpenAccess AI Collective (axolotl) General
General
-
Nemotrons API Speed Improvements: A member noted that the Nemotrons API has significantly increased in speed and also mentioned the release of the reward model.
-
Turbcat Model and Dataset Configuration: There was a discussion clarifying that Turbca is a person while Turbcat is the model name. Concerns were raised about dataset configuration and tokenization methods.
-
Tokenization and Sample Packing Debate: Members debated the tokenization process, focusing on issues like handling end-of-text tokens and context separation in sample packing.
-
Flash Attention and Multipack Visualization: A link to the Multipack with Flash Attention documentation was provided to demonstrate how to concatenate and handle samples during training.
-
Qwen Model's Biases and Adjustments: Issues were raised regarding the Qwen model's need for de-censoring and de-propagandizing. Biases related to CCP views were discussed, referencing an article on Hugging Face about Chinese LLM censorship analysis.
Chatbot Development and Technical Discussions
In this section, a variety of topics related to chatbot development and technical discussions are covered. These include bug fixes in coding practices, strategies for handling large text data from web scraping, integration of tools like Streamlit with LangServe for deploying web apps, and event filtering during streaming. Additionally, there are discussions around utilizing different GPUs for prefill and decoding in LLMs, the importance of finetuning models for specific tasks like fraud detection systems and niche product recommendations, and seeking RAG experts for optimizing AI chatbots in the financial sector. The content also includes sharing of guides on creating SQL agents, updates from research groups, launching of an AI concierge for food recommendations, and building conversational time machines using LangGraph chatbots.
Accounts Assistance and Account Credits Issues
Several members are requesting assistance with credits for their accounts, providing account IDs such as shubhi194-680421, cyzgab-17b4a1, and mnemic-8c53ac. In the LLM Finetuning section, members face issues with Predibase serverless inference, email registration, and unlocking credits. Another member in OpenAI reports problems viewing credits. The OpenInterpreter section discusses topics like the best uncensored model, obtaining long-term memory, and sharing the first Open Interpreter demo video. In the LAION section, the GBC10M dataset is announced, efforts for less restrictive licensing are noted, and the first author of the GBC10M dataset is acknowledged. The LAION research section covers topics like adversarial robustness disagreements, VAEs debate, LLMs overfitting, and challenges with the Chameleon model. Cohere discussions include various topics ranging from API usability for different languages to appreciating design choices. Other sections cover notable topics such as multilingual capabilities of Toucan TTS, the launch of Claude 3.5 Sonnet, and an engineering consultancy merger. Additionally, users highlight Groq's Whisper model support and discuss challenges in incorporating YOLOv10 and OCR into Llamafile in the Mozilla AI section.
Social Networks and Footer
This section of the webpage includes links to social networks such as Twitter and a newsletter. It also features a footer with links to AI news on social networks, a newsletter, and a note about being brought by Buttondown, a platform for newsletters.
FAQ
Q: What are the key performance improvements introduced by Claude 3.5 Sonnet by Anthropic?
A: Claude 3.5 Sonnet by Anthropic operates at twice the speed of Claude 3 Opus, excels in coding abilities, and showcases enhanced context utilization through features like 'Artifacts' for real-time interaction with AI-generated content.
Q: What are some new AI models mentioned in the essay and how do they perform compared to existing benchmarks?
A: New AI models like MoA and Infinity Instruct have shown enhanced performance compared to existing benchmarks like GPT-4, showcasing advancements in the field of AI.
Q: What discussions are highlighted in the Perplexity AI Discord section?
A: The Perplexity AI Discord section highlights discussions on various topics like the AI impact on search, technical issues, AI ethics debates, career paths, and psychedelic experiences.
Q: What topics are covered in the CUDA MODE Discord section regarding AI advancements?
A: The CUDA MODE Discord section covers topics like INT8 optimization, kernel profiling, AI breakthroughs, and models like Qwen2 and DiscoPOP for boosting LLM performance.
Q: What collaborations and events are mentioned in the essay related to AI and technology discussions?
A: Collaborations like CrewAI teaming up with LlamaIndex, LlamaIndex founder presenting at AI Engineer's World's Fair, and discussions on job opportunities, AI trends, and tech advancements are highlighted in the essay.
Q: What are some challenges and advancements discussed in the essay related to CUDA MODE and LLM Studio?
A: Challenges like quantization methods, speed improvements for FP2 and FP4 multiplications over FP16, GPU choices for LLMs, and challenges with DeepseekV2 models in LLM Studio are discussed in the essay.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!