[AINews] AdamW -> AaronD? • ButtondownTwitterTwitter
Chapters
AI Reddit, Twitter, and AI Discords Recap
High-Level Discord Discussions
Modular (Mojo 🔥) Discord
Model Applications and Insights
Perplexity AI and Unsloth AI Discussions
Keywords Blocking and Training Data for AI
Discussions on RAG Configuration, Hermes Model, and Fine-Tuned Models
Discord Community Debates
Discussion Highlights
Exploring AI Advancements and Projects at HuggingFace
HuggingFace and OpenInterpreter Events
Decoding Dual Views in Shape Manipulation
OpenRouter Announcements
CUDA Discussion Highlights
Challenges and Solutions
Mojo 🔥 General Updates
Interconnects on DPO and Verbosity in Language Model Training
Chatbot and AI Model Updates
AI Reddit, Twitter, and AI Discords Recap
This section provides a recap of activities and discussions related to AI on Reddit, Twitter, and AI Discords. It covers a wide range of topics including AI models and performance, stable diffusion, image generation, AI applications, AI ethics and policies, AI development and deployment, AI capabilities and limitations, as well as memes and humor shared within the AI community. The content discusses various advancements, limitations, discussions, and humorous takes related to the field of AI.
High-Level Discord Discussions
- Stability.ai (Stable Diffusion) Discord: The community discusses frustrations with Stable Diffusion's new inpainting UI, playful April Fools' features, and anticipates the release of Stable Diffusion 3.
- Perplexity AI Discord: Conversations revolve around troubleshooting performance of the Claude 3 Opus model, discussions on AI model benchmarks, and addressing API and credit purchase concerns within the community.
- Unsloth AI (Daniel Han) Discord: Engineers evaluate the Snapdragon Elite X Arm chip, fine-tuning models with Unsloth AI, and engage in debates on AI hardware advancements and fine-tuning techniques.
- Nous Research AI Discord: Topics include training StyleGAN2-ada, recommendations for ML/AI courses, successful replication of Microsoft's ternary LLM paper, and discussions on ethical concerns around voice synthesis.
- LM Studio Discord: The community shows interest in LMStudio's JSON output format, requests plugin support, and shares challenges with post-update GPU issues. Remote GPU support and architecture adaptability on Apple Silicon devices are also discussed.
- OpenAI Discord: Conversations range from Voice Engine advancements and AI ethics to model mix-ups and choosing the right AI tools for various tasks.
- Eleuther Discord: Discussions touch on AI safety, grammar nuances, AI's human-level intelligence, skepticism towards AI papers, and new optimization techniques from Meta.
Modular (Mojo 🔥) Discord
The section discusses the recent open-sourcing of Modular's Mojo standard library, including limitations and desired features. Technical conversations cover multithreading capabilities, OpenMP usage, and improvements in external_call() functionality. Updates on Mojo libraries, version 24.2, and the introduction of the Stump logging library are highlighted. The community also discusses performance benchmarks, one billion requests per minute challenge, and code challenges related to CPU enhancements and MLIR's syntax documentation.
Model Applications and Insights
The interchange on Discord platforms revealed various aspects of model applications and insights. The lm-sys brought up an Arena-Hard benchmark to evaluate language models, highlighting GPT-4's self-preference and superior performance over Claude. Meanwhile, discussions on token information analysis referenced mutual information and involved strategies like repeng and Typicality methods. Noteworthy advancements included sDPO for model training optimization and a closer alignment with human preferences without hefty financial investment. Additionally, initiatives like documenting open alignment techniques post-ChatGPT were highlighted by Nathan Lambert, providing insights into the historical evolution of the field. On another front, GalaxyAI rolled out a free API service offering access to high-caliber models like GPT-4, enhancing the community's ability to integrate AI into projects. LangChain AI introduced innovative prompting techniques through LangGraph, termed Chain of Tasks, aimed at crafting advanced conversational LLM Taskbots.
Perplexity AI and Unsloth AI Discussions
Perplexity AI
- Users discussed various topics such as different AI models' performance quirks, comparison of AI models, the crypto versus gold debate, speculation on the evolving tech landscape, and questions about Perplexity's features and user experience.
- Members shared diverse searches on perplexity.ai about topics like the limitations of Bohmian mechanics, SpaceX's workings, and the definition of 'Isekai'.
- Conversations involved explanations about Grok15, the Hyperloop concept, binary embeddings in machine learning, making threads shareable, utilizing AI for processing podcast transcripts, and engaging with April Fool's tech-related queries.
- Discussions touched on API response differences, partnership proposals, model support clarifications, troubleshooting credit purchases, and requests for token cost comparisons.
Unsloth AI
- Users encountered challenges with Unsloth models for fine-tuning Mistral models and discussed optimization methods, new AI hardware from China, dataset formatting, model quantization, and language support.
- Topics of conversation included fine-tuning methods, a new AI processor from Intellifusion, dataset formatting for model simulations, dealing with hallucination issues with quantized models, and exploring language support beyond English.
Keywords Blocking and Training Data for AI
In this section, discussions focused on blocking spam keywords like 'nitro' and the importance of training data diversity for AI models. There were debates on the relevance of including diverse data, such as 'Chinese poems from the 16th century,' versus more directly related data like math. Additionally, users shared experiences with fine-tuning Mistral models, challenges with GGUF file generation, and strategies for optimizing Gemma 2B models. Recommendations were also made for beginners to explore AI learning resources like CS231N lecture videos and Fast AI courses.
Discussions on RAG Configuration, Hermes Model, and Fine-Tuned Models
Choosing the Right RAG Configuration: Debates on using one big RAG or several specialized ones. Suggestions to combine vertical and horizontal approaches for effectiveness. The importance of a use case-specific solution was emphasized.### Hermes Model Token Discrepancy Explained: Technical discussions on padding related to the Hermes-2-Pro-Mistral-7B model reveal inconsistencies in vocab sizes. Padding to a multiple of 32 is mentioned to prevent issues from tensor parallelism on GPUs.### Deploying Fine-Tuned Models with a WebUI: Availability of a Docker for Ollama with a web UI for testing fine-tuned models mentioned. Script shared for easy Ollama setup, with discussions on loading models with adapters and CLI preferences.### Language Limitation in Hermes Models: Discussion on the Hermes 2 Pro model mainly functioning reliably with English inputs and outputs. Suggestions to prime the response with XML when using non-supported languages.### Finding and Fine-Tuning Japanese LLMs: Exploration of tuning models for Japanese language capabilities, considering options like shisa and qarasu. Proposals to adapt existing models like sakana or Capybara for better context and language skills.
Discord Community Debates
The community on Discord engaged in various discussions including concerns about AI ethics, AI models like ChatGPT and GPT-4, and the use of LMStudio and RAG systems. Members shared experiences and sought feedback on tools like Collate, VoiceCraft, and a custom GPT model for stock analysis. Additionally, debates on the future of AI, grammar intricacies, and GitHub repositories added a fun twist to the discussions.
Discussion Highlights
Skepticism Over MoE with Heterogeneous Expert Sizes:
- Conflicting opinions on MoE with heterogeneous expert sizes.
- Theoretical design suggests flexibility but practical reports indicate performance might not meet claimed benchmarks.
BitNet b1.58 Reproduced and Disputed:
- Independent reproduction by NousResearch disputes claimed benefits of BitNet b1.58 model.
- Suggests less efficiency than FP16 counterparts despite official papers.
- Skepticism remains about claims when scaled up.
Evaluating FID for Image Generation Benchmarks:
- Concerns raised about Frechet Inception Distance (FID) in evaluating image generation methods.
- Alternative proposal argues FID's limitations contradict human judgments, warrants reevaluation as primary metric.
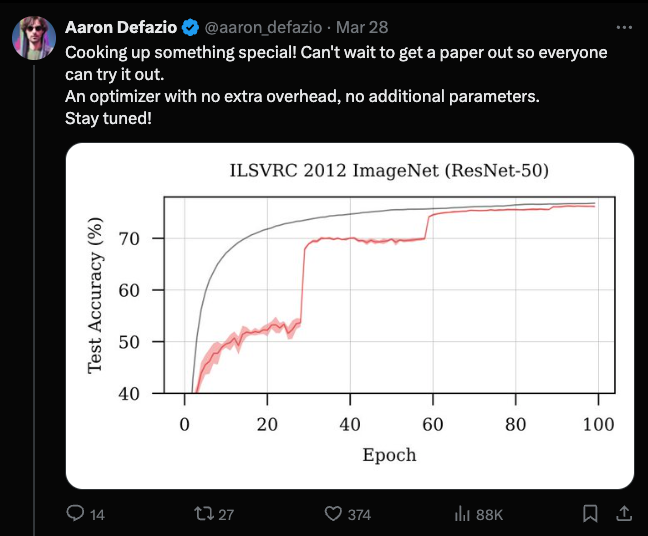
Anticipation for Potential Optimization Breakthrough:
- Anticipation and speculation over new optimization technique teased by Meta researcher.
- Suggests better results than Adam with no memory overhead.
- Conclusive information pending further details.
Tuning Text Summarization Models:
- Insights and references shared on starting models for SFT on TLDR text summarization.
- Consideration of models like Pythia with variability in performance, resource availability shaping experiment decisions.
Exploring AI Advancements and Projects at HuggingFace
In this section, various discussions and projects from different channels at HuggingFace are highlighted. Members explore advancements in AI such as UNETs, transformers, and new MoE models. Additionally, topics like AI image generation, AI-induced vulnerabilities, and technical challenges faced by users are discussed. Various innovative projects and research papers are shared, covering areas like linguistic brain structures, rechargeable magnesium batteries, and language models. The HuggingFace community also delves into topics like music mashups, microtransfer learning limits, and synthetic dataset creation methods. The section showcases a range of diverse projects, inquiries, and insights from the AI community at HuggingFace.
HuggingFace and OpenInterpreter Events
Finetuning Struggles with SAM Model:
- A user encountered a MisconfigurationException while trying to finetune a SAM model and was advised to adjust the accelerator parameter.
Multiple Font Sizes Cause Confusion:
- There was clarification about font size adjustments during a conversation about text representation.
Curation Techniques for Finetuning CLIP-like Models:
- Discussion on optimal dataset curation strategies for finetuning CLIP-like models with recommendations to check out OpenCLIP and FashionCLIP.
Diving into Video Classification:
- A user expressed difficulty in starting with VideoMamba for video classification and inquired about implementing models like VGG-16 or ResNet-34.
Normalization Queries in ConvUnet Implementations:
- Discussion on the normalization methods in ConvUnet implementations and recommendations to use nnUNet for prostate segmentation tasks in medical research.
Decoding Dual Views in Shape Manipulation
Members discussed the creation of two views in shape manipulation in tinygrad due to memory layout complexities and uneven stride presentation. The discussion highlighted the challenges and reasons behind this dual view generation, as showcased in View representations.
OpenRouter Announcements
New Rankings Unveiled
- App Rankings for Models have been launched, showcasing top public apps using specific models under the Apps tab for each model page. Token processing stats are provided. Check out the Claude 3 Opus App Rankings to see current leaders.
Community Spotlight on Discord Bots
- A Discord bot named Sora has been created by a member, integrating with the OpenRouter API to enrich Discord conversations. Find the bot on GitHub.
Craft Your Own Eval
- A community member introduced a way to write and share custom model evaluations through a project at nonfinito.xyz.
OpenRouter API and Client Updates
- A new /api/v1/completions API endpoint is introduced with prompt parameter-only support, and improvements have been made to OpenAI API client support. Groq for Nitro models usage is halted due to rate limiting issues.
King of Expertise
- Databricks' DBRX 132B, an open-source large language model with superior performance in reasoning and coding tasks, is now available. Details can be found on the DBRX Instruct page and in their launch announcement.
Links Mentioned:
CUDA Discussion Highlights
- Interest in Upcoming AI Discussions: The group expressed excitement for future discussions on topics like UI/UX patterns, RAG architectures, and more, as listed in a shared spreadsheet.
- IDEs for CUDA Development: Discussions on preferred IDEs for CUDA development, with VSCode and CLion being popular choices.
- Beginner's CUDA Programming Course: Cohere introduced a CUDA course for beginners, with a learning session starting soon.
- Open Source Mojo Standard Library: Modular announced that core modules from the Mojo standard library are now open-source.
- AI Supercomputer 'Stargate': Buzz about Microsoft and OpenAI collaborating on building an AI supercomputer named "Stargate" with a $100 billion projected cost.
- Troubles During Discord Event: Difficulties experienced with voice channel limitations during a high-attendance Discord event.
- Discussion on CUDA Troubleshooting in Triton Kernels: Members discussing inaccuracies and issues related to TF32 precision in Triton kernels.
- PyTorch's New Optimization Configuration: PyTorch released a configuration for single-card finetuning of LLaMA 7B models.
- Quality Concerns for YouTube Lecture Video: Quality issues reported for a lecture video on YouTube, with recommendations to check back later for higher resolution versions.
- Importance of Personal Effort in Study Groups: Emphasis on personal effort before seeking answers in study group discussions.
- Exploration of Ring-Attention Training Initiatives: Discussions about training on multiple GPUs using a 7B model, sourcing long-context datasets, improving LLM training configurations, and implementing needle in a haystack evaluation.
Challenges and Solutions
Members of the Axolotl Discord community engage in various discussions related to AI development, including optimizing memory usage, challenges with distributed training, and fine-tuning large language models. They explore solutions such as PagedAdamW for memory optimization, integrating DBRX into Axolotl, and addressing issues with gradient accumulation and multi-GPU setup compatibility. Conversations also touch on model selection for text classification, developing tools for model testing and chat interfaces, and troubleshooting training stagnation issues. The community remains active in sharing knowledge and seeking advice on system setups and efficient model training strategies.
Mojo 🔥 General Updates
This section provides various updates related to the Modular (Mojo 🔥) community. It includes details on the open-sourcing of Modular's standard library with some restrictions, challenges faced by users in installing Mojo on Linux Mint, a security alert regarding xz-utils backdoor, the development platform Mojodojo.dev open for contributions, and discussions on privacy standards, optimizations, setting up and contributing to Mojo, syntax highlighting, and interop queries. Additionally, the section covers updates on community projects like MLIR syntax documentation, library module updates, 'Reference' component evolution, new logger library introduction, and discussion on decorators. Lastly, it highlights challenges and solutions in performance and benchmarks, serving Triton backend, migration concerns, token information density measurements, and discussions related to information theory in text generation and model evaluations.
Interconnects on DPO and Verbosity in Language Model Training
A new preprint discussed the interplay between Direct Preference Optimization (DPO) and verbosity in large-scale language model training, highlighting how increased verbosity can lead to model divergence. Another topic addressed was the research on Reinforcement Learning from Human Feedback (RLHF) and its susceptibility to biases favoring eloquence over helpfulness. The conversation also delved into the introduction of stepwise DPO (sDPO), aiming to align large language models more closely with human preferences, potentially leveling the playing field for smaller labs in achieving performance gains. There were queries and comments on the repetition of DPO usage and suggestions for exploring alternative methods like RLHF, as well as interest in efficient batching of preference data and optimizing DPO strategies. The section highlighted ongoing research and discussions around improving language model alignment and training methods.
Chatbot and AI Model Updates
A user customized a chatbot to include Scout Law in responses, a chatbot designed to be verbose and trusty, a discussion on a chatbot generating clarifying questions, troubleshooting installation issues, and seeking assessments for novel LLM architectures. Additionally, advancements in AI models include the introduction of Jamba combining SSM and Transformer models, robust reproduction of BitNet model, understanding Nectar dataset's data diversity, and speculation on GPT contextual understanding. Papers discussed focus on adapter tuning in CIL and enhancing open-source LLMs, while off-topic talks feature AI21's Jamba model and Databricks' new LLM DBRX setting new benchmarks.
FAQ
Q: What are some discussions and activities related to AI on Discord platforms like Stability.ai, Perplexity AI, Unsloth AI, Nous Research AI, LM Studio, OpenAI, Eleuther, and HuggingFace?
A: Discussions on Discord platforms cover topics such as AI model performance, stable diffusion, image generation, AI ethics, AI development and deployment, AI capabilities and limitations, memes/humor in the AI community, troubleshooting AI models, AI hardware advancements, fine-tuning techniques, training different language models, ethical concerns around voice synthesis, UI/UX patterns, RAG architectures, AI-induced vulnerabilities, text summarization models, video classification, CUDA development, and more.
Q: What are some technical discussions and highlights from the AI community concerning AI models and tools like Modular's Mojo standard library, Hermes models, RAG systems, and ChatGPT?
A: Technical discussions have included the open-sourcing of Modular's Mojo standard library, which involved limitations and desired features, discrepancies in token sizes for Hermes models, deploying fine-tuned models with a WebUI like Ollama, language limitations in Hermes models, finding and fine-tuning Japanese language models, debates on using one big RAG or specialized ones, skepticism over MoE with heterogeneous expert sizes, reproducing and disputing models like BitNet b1.58, evaluating FID for image generation benchmarks, discussions on text summarization models, and more.
Q: What notable advancements and projects have been shared within the AI community at HuggingFace?
A: Notable advancements and projects shared at HuggingFace include discussions on UNETs, transformers, new MoE models, AI image generation methods, AI-induced vulnerabilities, technical challenges faced by users, linguistic brain structures, rechargeable magnesium batteries research, music mashups, microtransfer learning limits, synthetic dataset creation methods, and more.
Q: What are some recent updates and challenges discussed within the Modular (Mojo) community?
A: Recent updates and challenges within the Modular (Mojo) community include the open-sourcing of Modular's standard library with restrictions, challenges installing Mojo on Linux Mint, a security alert regarding xz-utils backdoor, the development platform Mojodojo.dev open for contributions, discussions on privacy standards, optimizations, setting up and contributing to Mojo, syntax highlighting, interop queries, community projects like MLIR syntax documentation, library module updates, new logger library introduction, challenges in performance and benchmarks, serving Triton backend, migration concerns, token information density measurements, and discussions related to information theory in text generation and model evaluations.
Q: What are some ongoing research and discussions highlighted around improving language model alignment and training methods?
A: Ongoing research and discussions focus on improving language model alignment and training methods through Direct Preference Optimization (DPO), verbosity in large-scale language model training, Reinforcement Learning from Human Feedback (RLHF), stepwise DPO (sDPO), aligning language models with human preferences, exploring alternative methods like RLHF, efficient batching of preference data, optimizing DPO strategies, and more.
Q: What are some notable advancements and projects shared within the AI community concerning AI models like Jamba, BitNet, Nectar dataset, GPT models, and Databricks' LLM DBRX?
A: Notable advancements and projects within the AI community include the introduction of Jamba combining SSM and Transformer models, robust reproduction of BitNet model, understanding Nectar dataset's data diversity, speculation on GPT contextual understanding, adapter tuning in CIL, enhancing open-source LLMs, AI21's Jamba model, and Databricks' new LLM DBRX setting new benchmarks.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!